
Table of Contents
In the current era where the field of Data Analytics is booming, people, especially fresh graduates, are considering how to become data engineers and seeking possible ways and opportunities to learn data engineering. However, when they start this path, certain assumptions come into their mind. And the questions in their mind arise: Is data engineering hard? How to become a data engineer? How to learn data engineering? Let’s explore it and find the signal in the noise.
Being a beginner, when you decide to pursue the field of Data Engineering or Big Data, you may find this field to be quite complicated provided a mountain of tools available out there. It must have been confusing to learn a large number of tools. You must have wondered which tool to learn first, the “why” behind those tools, from where you should start, and what EXACT skills are needed for the job.
Today, I am going to answer these questions, and not only that, I’ll tell you how to get good at data engineering. And as a BONUS, I will include some links for you in their subsequent sections of the article, which will act as a very easy learning path for you to follow.
Now, in order to answer how to learn data engineering, we’d first need to establish what data engineering is and what is big data evolution.
1 What is Data Engineering

To answer this question, we must go back to where it all started. Not too many years ago, there was a sudden boom in the field of Data Science and Machine Learning. Everyone was talking about Data Science being the hottest field of all time. As a result, the job market arose for data scientists and data analysts.
The expectation (albeit seemingly childish) was that data scientists would be training the data and creating machine learning models. However, this was later debunked and data scientists turned out to be working more on the engineering side of things, including reading the data from data sources, cleaning the data, creating data pipelines, and looking over the DevOps side of things.
Not only that, managing huge volumes of data with varying sources and dynamic variety was a challenge of its own. Since cloud technology was on the rise and big data was being generated at an unprecedented pace. So to be able to train the (big) data, first, it has to be stored and processed in a cost-efficient manner.
This ultimately gave recognition to a related but different discipline, Data Engineering. This field wasn’t new. It was just known by different names, such as ETL Consultant, Data Warehouse Engineer, etc. And, after the rise of Big Data, it was renamed (or I should say, rebranded) to Data Engineering (aka Big Data Engineering) & with this boom of Big Data, developing & maintaining big data systems such as data lakes also became a part of this job along with working on technologies like Data Warehousing.
Data Engineering is the discipline of creating sophisticated analytical systems with the ability to fetch, store, process, and analyze different volumes and variety of data in a distributed and cost-efficient manner.
This made Data Engineering quite popular. And this time, just like people used to talk about Data Science, now Data Engineering was getting traction equally, if not more.
Now that we have established what is data engineering, let’s dive into the actual topic. And before that, let’s talk about what Big Data is and how it evolved.
2 What is Big Data and its Evolution
Big data is a term that has become increasingly prevalent in recent years as technology continues to advance and the amount of data generated by businesses and individuals grows exponentially. At its core, big data refers to the vast amount of data that is generated on a daily basis, and the challenges that come with managing, storing and analyzing this data.
One of the key challenges of big data is its sheer volume. With the proliferation of digital devices, the internet of things, and the increasing adoption of cloud computing, the amount of data being generated every day is staggering. In fact, as of 2021, it was estimated that over 2.5 quintillion bytes of data are generated daily, and this number is expected to grow in the coming years.
Another challenge of big data is its complexity. With such a large amount of data being generated, it can be difficult to make sense of it all and extract valuable insights. This is where advanced analytics and data management tools come into play, allowing businesses to analyze and interpret their data in order to make better decisions and improve their operations.
Despite the challenges, big data offers a wealth of opportunities for businesses of all sizes. By leveraging advanced analytics and data management tools, businesses can gain valuable insights into their customers, operations, and market trends. This can help them to make more informed decisions, improve their products and services, and stay ahead of the competition.
Furthermore, big data can be used to improve processes and operations, allowing businesses to become more efficient and reduce costs. For example, data analysis can be used to identify bottlenecks in production processes and optimize them, reducing waste and increasing efficiency.
In conclusion, big data is a rapidly growing field with many challenges and opportunities. As the amount of data generated continues to increase, businesses will need to invest in advanced analytics and data management tools in order to make the most of this data and gain valuable insights. By doing so, they can improve their operations, make better decisions, and stay ahead of the competition.
3 Data Engineering Learning Journey
When you begin your data engineering journey, you come across a huge range of tools such as below:
Overwhelming, right? And… speaking from experience, this creates a lot of confusion in the mind of a beginner. However, if you think about it, these are just different tools that solve more or less the same problems and/or use cases.
Instead of thinking about the tools, let’s categorize data engineering into the following two use cases.
- Storage
- Compute
Back in the day, we didn’t have huge volumes of data and we used to store them on hard disks — that too mostly on our personal computers — so the storages were small and the compute was also done on PCs. Then, the data increased and in-house servers took their place. But as time went by, data kept on increasing in volume, variety, veracity, and velocity, and hence, this data went on to be called “Big Data”.
In the current world, especially when such a huge volume of data is being generated from various sources, e.g. Social Media websites, IoT devices, etc., and that too with tremendous velocity, we need to think smartly about storing and processing this data for the purpose of analytics. Hence, no matter how many tools there are in the world, almost all of them solve either the storage problem (in a distributed manner) or compute problem (that too in a distributed manner).
When you understand this, you stop thinking in terms of tools and start thinking in terms of solving storage and compute problems, and the right tools just come to your mind when you research your specific use case.
4 How To Become a Data Engineer – Deep Dive
Now that I have established a premise, I’ll present to you the tools that are most popular in this field and are used the most in the industry. This will help you eliminate feeling overwhelmed. But first, let me list them down below:
- Learn SQL (Well – This is the most important of them all)
- Learn Python (with Pandas) and optionally but I recommend: Any JVM Based Language (Scala & Java)
- Learn about Distributed Data Storage – Apache Hadoop, Amazon S3, Azure Blob Storage
- Learn about Distributed Data Processing – Apache Spark / PySpark
- Learn how to orchestrate and schedule jobs – Apache Airflow
- Learn bash commands and some basic scripting
- Understand the types of data: Structured, Unstructured, and Semi-Structured (This is not a tool but important)
- Bonus: Learn Real-Time Streaming – Apache Kafka
Apart from the list above (details of which are below), I highly recommend that you learn about The Cloud technologies such as AWS and Azure. As most of the tools above are now provided as services by most cloud providers and that’s what companies are opting for due to the scalability and elasticity factor.
Now, let’s dive deep on how to become a data engineer.
Learn SQL
Don’t let the above picture confuse you.
In any domain of data that you enter, be it Data Analytics, Business Intelligence, Data Science, or Data Engineering, there is a CONSTANT. And This constant is SQL. SQL stands for Structured Query Language.
This is a universal language that is used in almost every discipline of Software Engineering. SQL is the language that is used to query the data, manipulate it, transform it, filter it, and enrich it. It is often used on tables in an SQL Database but nowadays, even Views are made on semi-structured & unstructured data (more on these below) which look like tables and SQL can be used on them to query the data.
No matter what tool you are using, you’d be using SQL in any shape or form. If you are using Python, you’d most likely be programmatically creating SQL queries. In Apache Spark, you’d most likely be working with SQL on the views made on Spark DataFrames, and other engines that also utilized SQL.
To learn SQL, I highly recommend the following FREE videos:
- MySQL Tutorial for Beginners [Full Course] – YouTube – This is by Mosh Hamedani, the best of the best.
- SQL For Beginners Tutorial | Learn SQL in 4.2 Hours | 2021
- SQL Tutorial – Full Database Course for Beginners
Learn Python
![]()
Python is a general-purpose scripting language that has been gaining popularity for quite some time. And I think it is safe to say that Python is the most popular language.
In data engineering, Python is gaining popularity with speed. Since, most data scientists before knew Python, data engineering was usually geared more towards JVM-based languages (Scala & Java). But due to its versatility and robust libraries, more and more organizations are opting for Python as a language for their data analytics and engineering needs.
One of the key benefits of using python is its simple syntax and ease of use. Due to this, it has a very large community of developers who provide support and solutions to common problems. This makes it very easy and comfortable for data engineers to learn Python, get a good command of it, and apply it in their day-to-day job without it becoming a bottleneck in their workflow.
Python also has a rich ecosystem of libraries and frameworks that cater to the needs of data engineers. Popular libraries like Pandas and NumPy provide efficient tools for data manipulation and analysis. Not only that, it provides very easy-to-use libraries for web scraping and calling REST APIs. Due to its popularity and increasing need, it has very strong integration capabilities with popular data stores and big data platforms. Especially, Apache Spark, with which it can work seamlessly provided Spark has a Python API known as PySpark.
In conclusion, Python is a versatile and powerful language that has a strong presence in the field of data engineering. Its simplicity, robust libraries, and integration capabilities make it a preferred choice among data engineers. And hence, I highly recommend that you learn Python.
Following are some of the most popular Free YouTube Playlists/videos for beginners to get hands-on Python experience:
- Python Programming Beginner Tutorials by Corey Schafer (I highly recommend this)
- Pandas Tutorials By Corey Schafer (Must learn this)
- Complete python roadmap | How to become an expert in python programming
Some of the Free playlists from channel Tech With Tim that I also recommend:
Learn Distributed Data Storage (Apache Hadoop, Amazon S3, Azure Blob Storage)

When we think about Big Data, Apache Hadoop always comes to mind. Because that’s how Big Data was popularized. But actually, Hadoop simply distributes the data in its storage known as HDFS which stands for Hadoop Distributed File System.
Hence, it’s not about Hadoop, it’s about a distributed storage system that can store data of different varieties among several nodes in a cluster in a distributed fashion so that a distributed processing engine can process the data on top of this storage layer. And since Hadoop, some other cloud-based technologies also surfaced which gave Hadoop really tough competition. In fact, these technologies are now given more preference over Hadoop, technologies like Amazon Simple Storage Service (S3) or Azure Blob Storage/Azure Data Lake Storage/Azure Data Lake Storage Gen2.
Some of the benefits of using distributed storage are:
- Ability to manage high volumes of data
- Reducing the risk of data loss due to proper data replication systems in place. Hence providing reliability.
- Data can be scaled as needed.
- Data is partitioned and properly distributed in the cluster for independent processing
I highly recommend that you learn Hadoop architecture and its components.
I HIGHLY recommend the following free resource to learn about Hadoop and distributed storage in general.
you MUST go through the whole video. It’s like a full course in a YouTube video. And it’s a gem. Not only you’ll learn about the big data landscape in general, but you’ll also get an idea of most of the tools in the Hadoop ecosystem.
Learn Distributed Data Processing – Apache Spark
In order to become a data engineer, you ought to learn Apache Spark for several reasons. First, Apache Spark is one of the most popular and widely used big data processing frameworks. It is highly scalable and can be used to process large amounts of data quickly and efficiently. This makes it a valuable tool for data engineers who need to work with large datasets.
Second, Apache Spark provides a rich set of APIs and libraries that make it easy for data engineers to perform common data processing tasks. For example, Spark’s MLlib library provides a wide range of machine learning algorithms that data engineers can use to build predictive models from data. This can save data engineers a significant amount of time and effort compared to developing machine learning algorithms from scratch.
Third, Apache Spark is highly extensible and can be used in combination with other big data technologies, such as Apache Hadoop and Apache Flink. This allows data engineers to build complex, end-to-end data pipelines that can extract, transform, and analyze data from a variety of sources.
Overall, learning Apache Spark can provide data engineers with a powerful and versatile tool for working with big data, and can open up new opportunities for career advancement.
I HIGHLY recommend going through the following Free learning resources:
- Spark Tutorial | Spark Tutorial for Beginners | Apache Spark Full Course – Learn Apache Spark 2020
- PySpark Tutorial For Beginners | Apache Spark With Python Tutorial | Intellipaat
Following are 2 premium (but very affordable) courses that I HIGHLY recommend that you buy on Udemy.
- Apache Spark 3 – Spark Programming in Python for Beginners – Udemy
- Apache Spark 3 – Beyond Basics and Cracking Job Interviews – Udemy
I suggest that you buy these courses and complete them in the sequence provided. And make sure you practice and practice!
Learn how to orchestrate and schedule jobs – Apache Airflow

In data engineering, when a data pipeline or ETL processing runs, we say, the job is running. “Job” is the most common terminology used to refer to the running of a data engineering pipeline.
Now, the question arises, when do these pipelines run? Do data engineers run them manually? If so, how do they know when to run it?
Usually, these jobs are scheduled to run at specific time intervals. And there are certain tools that help in scheduling and integrating different jobs. One such tool is Apache Airflow which is one of the most popular and highly sort after tools in the market.
What is Apache Airflow
Apache Airflow is an open-source platform to programmatically author, schedule, and monitor workflows. It was designed to be a highly scalable and extensible platform, allowing data engineers to build and maintain complex data pipelines with minimal effort.
There are several reasons why data engineers should learn Apache Airflow:
First, Airflow provides a rich set of tools and features for building and managing data pipelines. It allows data engineers to define workflows using code, which makes it easy to create complex pipelines and make changes to them as needed.
Second, Airflow has a strong ecosystem of community-developed plugins and integrations, which can be used to extend its capabilities and connect to other data processing and storage systems. This allows data engineers to build end-to-end data pipelines that can extract, transform, and analyze data from a variety of sources.
Third, Airflow has a rich user interface that makes it easy to monitor and manage data pipelines. It provides detailed information about the status of each task in a pipeline, as well as the ability to trigger and manage pipeline runs. This can help data engineers to ensure that their pipelines are running smoothly and efficiently.
On a high level, data engineers use Airflow to do the following four things:
- A DAG (or Directed Acyclic Graph) is defined (which is just a superset of different tasks)
- A schedule for this DAG is configured. Which is usually a CRON expression to tell the DAG when to run.
- Tasks are defined inside the DAG. These are the actual things that run the logic.
- Dependency among tasks is defined. That means, which task to run first and which task to run after. We can also configure the tasks to run in parallel.
Overall, learning Apache Airflow can provide data engineers with a powerful and flexible tool for building and managing data pipelines, and can help them to become more productive and effective in their work.
The following Free resource is highly recommended to learn Apache Airflow:
Learn bash commands and some basic scripting
This is a no-brainer. Especially in the data engineering field where you’d be working with a lot of Linux servers. And trust me, learning bash commands is like cake. You don’t need to deep dive. Just a few basic commands like:
- Listing files in a directory
- Editing files (using vi or vim)
- Creating and switching directories
- Copying files
- etc.
Once you get the gist of it, you’d develop muscle memory and your fingers will type the commands for you.
Personally, I google the heck out of these commands whenever I need to perform certain functionality. I don’t have to memorize them (although, my fingers do, due to muscle memory *wink wink*).
Once you are comfortable with the basics, make sure you learn these top 50 commands. As they’ll eventually help you in your career in one way or another. Especially if you intend to go to the operations side.
Some of the basic commands are below:
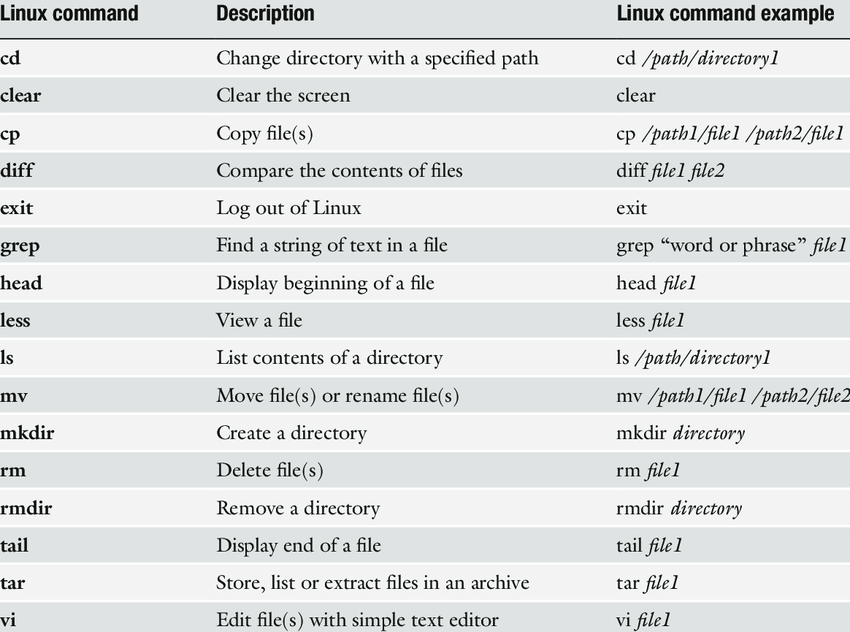
Bonus: Learn Real-Time Streaming – Apache Kafka

In the current world, there are two approaches to data engineering:
- Batch Processing
- Stream Processing
Usually, the data is fetched and processed from the source in batches. Often at night time when the OLTP system is not busy.
However, nowadays, more and more organizations are opting for real-time data processing and enrichment. That’s where stream processing comes into place. And Apache Kafka is one of the most popular tools when it comes to real-time streaming.
Apache Kafka is an open-source stream processing platform that is commonly used for building real-time data pipelines and streaming applications. It can handle high volumes of data and allows for the storage and processing of data in real time.
Kafka is based on a publish-subscribe model, in which producers send data to Kafka topics, and consumers can subscribe to these topics to receive the data. This allows for the decoupling of data producers and consumers, which can improve the scalability and reliability of the overall system.
In addition to its core stream processing capabilities, Kafka also provides support for data integration, data security, and monitoring. This makes it a popular choice for building robust and scalable data pipelines and streaming applications.
A data engineer’s value increases exponentially when he/she knows the concepts of real-time stream processing and tools like Apache Kafka. And this helps you immensely in becoming a data engineer in your career.
The following Free resource is a great starting point to learn Apache Kafka. I highly recommend that you go through all the content in it:
5 To conclude
To become a data engineer, you ought to:
- Learn how different computers work together to form a single computer (distributed computing)
- Learn about processing and storage in the distributed computing world and how they are scaled and the load is balanced.
- Learn an in-memory processing engine (e.g. Spark, Hive)
- Learn any tool used for scheduling and orchestration (e.g. Apache Airflow).
- Learn the basics of Linux and Bash scripting. With some basic networking
- Learn the concept of Batch Processing vs. Stream Processing. (Apache Spark & Apache Kafka)
AND! last but not the least, I HIGHLY STRESS that you learn Python and SQL. Where SQL is of utmost importance. Remember, a data engineer is NOT a data engineer if he/she doesn’t know SQL.







Discussion about this post